RabbitMQ 深入浅出
- RabbitMQ MQ
RabbitMQ 知识架构
1. AMQP 协议基础
RabbitMQ 是 AMQP 0-9-1 协议的实现,其核心模型基于信道(Channel)、**交换机(Exchange)和队列(Queue)**的协作。
- AMQP 协议分层:分为 Module Layer(定义业务命令)、Session Layer(处理命令传输与同步)、Transpot Layer(二进制数据传输)。
- 信道(Channel):基于 TCP 连接的虚拟链路,复用 TCP 连接以降低开销,每个信道独立处理消息路由,支持多线程并发操作。
- 虚拟主机(VHost):逻辑隔离的独立环境,每个 VHost 拥有自己的交换机、队列和权限。
- 帧(Frame):AMQP 数据传输的最小单位,包含帧头、帧体和帧尾,用于封装消息和协议指令。
2. 消息流转原理
消息从生产者到消费者的完整生命周期如下:
(1)生产者发送消息
- 连接建立:生产者通过 TCP 连接到 RabbitMQ 节点,并创建信道。
- 消息封装:消息包含有效负载(Playload) + 元数据(Headers、Routing Key、Delivery Mode 等)。
- 发送到交换器:生产者通过
basic.publish方法将消息发送到指定的交换器。- 关键参数:
exchange(目标交换器)、routing_key(路由键)、mandatory(消息无法路由时是否返回错误)。
- 关键参数:
(2)交换器路由消息
交换器根据类型和绑定规则将消息路由到队列:
- Direct Exchange:精确匹配
routing_key和binding_key,类似哈希表查找。 - Fanout Exchange:广播到所有绑定的队列,忽略
routing_key。 - Topic Exchange:基于通配符的层次化匹配,内部使用Trie 树或哈希表优化路由效率。
- Headers Exchange:通过
headers键值对匹配,性能较低,适用于复杂条件路由。
(3)队列存储消息
消息进入队列后,按**先进先出(FIFO)**顺序存储,但优先级队列(Priority Queue)可调整顺序。
- 持久化队列:元数据和消息(若标记为持久化)写入磁盘,重启后恢复。
- 内存队列:仅存储在内存,重启后丢失。
(4)消息者拉取消息
- 订阅队列:消费者通过
basic.consume订阅队列,进入阻塞等待状态。 - 消息推送:RabbitMQ 通过
basic.deliver方法主动推送消息到消费者(Push 模式)。- 消费者也可通过
basic.get主动拉取消息(Pull 模式),但效率较低。
- 消费者也可通过
- 消息确认(ACK):
- 自动 ACK:消息发送后立即从队列删除,风险高(消息可能未处理成功)。
- 手动 ACK:消费者处理完成后发送
basic.ack,队列删除消息;若未 ACK 且连接断开,消息重新入队(Redelivery)。
3. 持久化与可靠性机制
(1)消息持久化
- 队列持久化:声明队列时设置
durable=true,确保队列元数据不丢失。 - 消息持久化:发送消息时设置
delivery_mode=2,将消息体写入磁盘。- 写入时机:消息先写入内存缓冲区,异步刷盘(可通过 Publisher Confirm 确保刷盘完成)。
(2)发布者确认(Publisher Confrim)
- 事务模式:通过
txSelect、txCommit等命令实现原子性,但性能差。 - Confirm 模式:
- 生产者开启
confirm模式,每条消息分配唯一 ID。 - RabbitMQ 通过
basic.ack(成功)或basic.nack(失败)异步通知生产者。 - 生产者可批量确认(
confirm.select设置multiple=true),提升吞吐量。
- 生产者开启
4. 死信队列(DLX)原理
当消息无法被正常消费时,会被转发到私信交换器(Dead Letter Exchange)
- 触发条件:
- 消息被消费者拒绝(
basic.reject或basic.nack)且requeue=false。 - 消息 TTL 过期。
- 队列达到最大长度限制。
- 消息被消费者拒绝(
- 死信路由:死信消息携带原始的路由键和头部消息,有 DLX 重新路由到死信队列。
5. 集群与高可用原理
(1)集群架构
- 元数据同步:所有节点共享交换器、队列、绑定等元数据,但队列数据仅存储在创建节点。
- 客户端连接:客户端可连接任意节点,若请求的队列不在该节点,通过内部路由转发。
(2)镜像队列(Mirrored Queue)
通过策略(Policy)定义 ha-mode(如 all),队列数据在集群节点间同步,基于 Raft 协议选举主节点。
- 数据同步:队列的镜像副本分布在多个节点,通过 **Guaranteed Multicast **算法同步。
- 故障转移:主节点(Master)宕机后,从镜像中选举新的主节点(基于 Raft 协议)。
(3)网络分区处理
- 自动恢复策略:
pause_minority:少数派节点自动暂停,避免数据冲突。autoHeal:重启后自动选择分区中的多数派恢复。
- 手动干预:通过
rabbitmqctl forget_cluster_node移除故障节点。
6. 内存与磁盘管理
- 内存控制:RabbitMQ 默认优先使用内存存储消息,超出阈值(
vm_memory_high_watermark)后持久化到磁盘。 - 流控机制:当消费者处理速度过慢时,通过 TCP 背压(Back Pressure)机制阻止生产者继续发送消息。
7. 性能优化原理
(1)预取(QoS)
- channel.basicQos(prefetchCount) :限制消费者未确认消息的最大数量,避免消费过载。
- 公平分发:若多个消费者订阅同一队列,RabbitMQ 会轮询分发消息(Round-Robin)。
(2)批量操作
- 批量发布消息:合并多个消息到单个帧,减少网络开销。
- 批量确认:通过
multiple=true参数确认多条消息。
8. RPC 模式原理
- 回调队列:消费者在
reply_to头部指定响应队列。 - 关联 ID:生产者通过
correlation_id匹配请求与响应。
+---------+ +------------+ +---------+
| Client | --(1)--> | RabbitMQ | --(2)--> | Server |
| | <--(4)-- | (RPC Queue)| <--(3)-- | |
+---------+ +------------+ +---------+
步骤:
1. 客户端发送请求到 RPC 队列,携带 `reply_to` 和 `correlation_id`。
2. 服务端消费请求,处理完成后将结果发送到 `reply_to` 队列。
3. 客户端监听 `reply_to` 队列,通过 `correlation_id` 匹配响应。
9. 流量削峰原理
- 队列缓冲:通过队列暂存突发流量,消费者按处理能力逐步消费。
- 限流策略:结合 QoS 预取和消费者水平扩展,控制处理速率。
10. 保证消息有序性
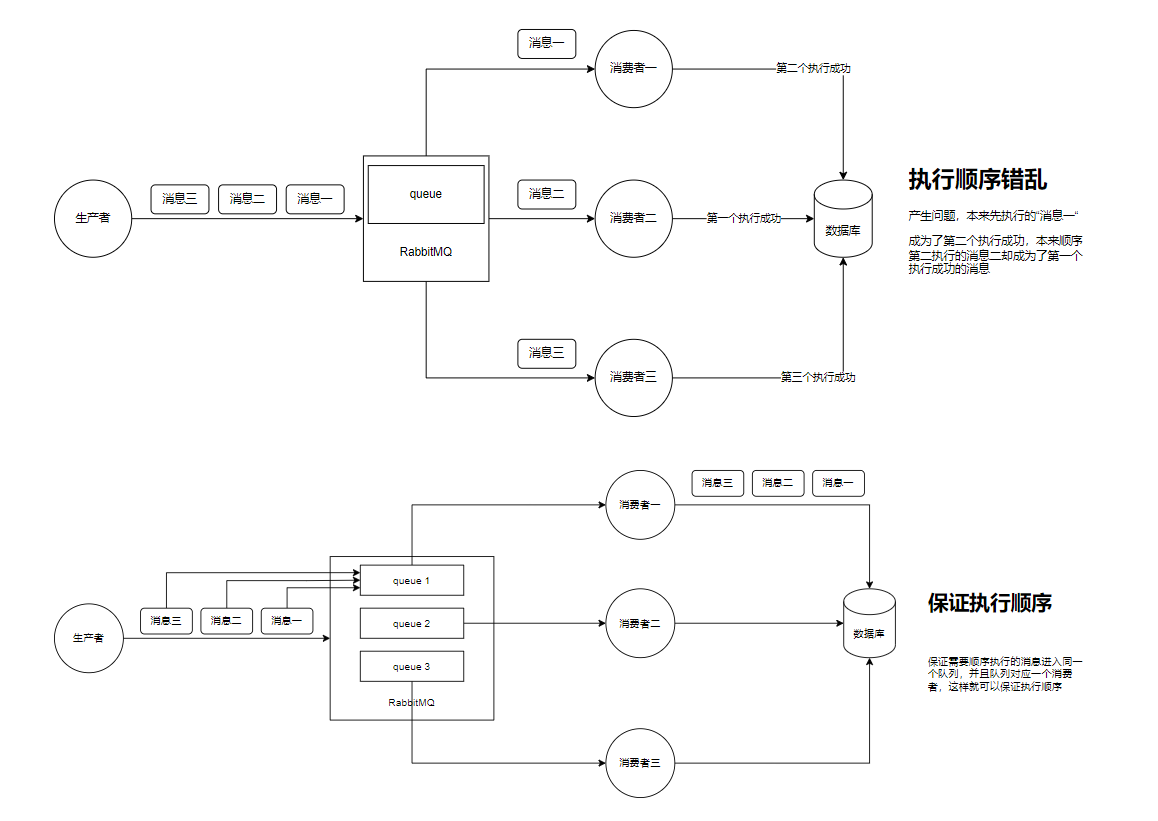
11. 高可用
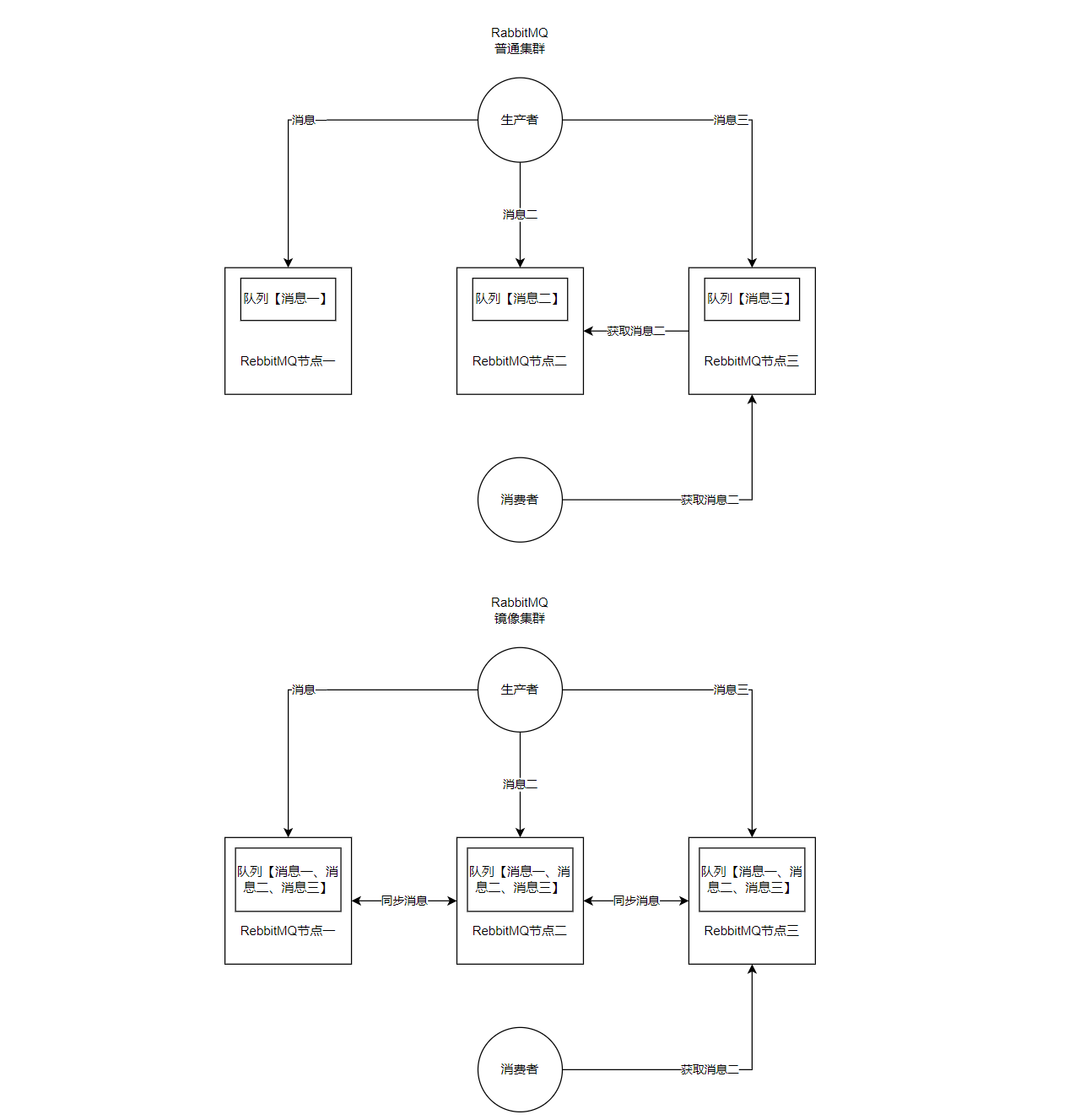
12. 重要知识点
- 为什么使用消息队列?
- 核心场景:解耦(服务间异步通信)、削峰(缓冲高并发请求)、异步(非阻塞处理)。
- 缺点:系统可用性降低(依赖 MQ)、复杂性增加(需处理消息丢失、重复、顺序性问题)。
- 如何保证消息不丢失?
- 生产者:使用 Confirm 模式(异步确认)或事务(同步确认)。
- Broker:持久化队列与消息,结合镜像队列。
- 消费者:关闭自动 ACK,处理完成后手动发送 ACK。
- 如何避免消息重复消费?
- 生产者去重:MQ 内部生成
inner-msg-id拦截重复投递。 - 消费者幂等:业务层通过唯一标识(如订单 ID)校验,结合数据库唯一键或 Redis 原子操作。
- 生产者去重:MQ 内部生成
- RabbitMQ 集群模式?
- 普通集群:元数据同步,但队列数据仅存于创建节点,故障时需重新拉取数据。
- 镜像集群:队列数据全节点同步,高可用但性能开销大,拓展性差。
- 消息顺序性如何保证?
- 单队列消费者:同一业务的消息路由到同一队列,由单个消费者顺序处理。
- 全局序列号:消息中添加序号,消费者按序处理。
- 消息堆积如何处理?
- 临时扩容:增加队列 Partition 和消费者实例,并行消费积压数据。
- 批量导出:将积压消息导出至临时 Topic,分片处理。